Best Practices for Using GenAI in Scientific Coding
Amplify your skills, but do not erode them.

Today’s ubiquity and accessibility of Generative AI (GenAI) is amazing for editing texts and writing code. But I do observe in myself, that one is tempted to become lazier instead of thinking things through - particularly so with coding. Therefore, in this blog, I want to briefly outline my thoughts on best practices for applying GenAI to scientific coding, modelling and data analysis (similar principles apply to writing text). I hope you might find this useful, too! (At least do not miss the summary figure at the end!)
It is so easy now to prompt GPT4, or another model, for routine coding tasks. In my scientific work, I can use it to make figures and graphs at a breathtaking pace. It is such a game changer. I now just think of any graph and quickly describe it to GPT4 and it creates it. Farewell to the hours spent searching for the right features and explanations on how to do something on Stackoverflow (let us remember though that GenAI would not work, if stackoverflow had not existed and it continues to be important to ensure code quality). It is clear of course that there still many specific cases and things that GenAI is not capable of. Whole system design and software engineering, for example, is some way off (or so I hope, but GenAI agents might change that, too?).
In any case, I think it is imperative that coders, amateur and professional, keep their skills sharp. So that we might correct GenAI, if necessary, and also so that GenAI keeps on getting better. GenAI will not get better at coding, if humans do not keep getting better.
This is why here is my 5 suggestions for best practices for scientific coding:
Avoid Delegating High-Level Design Decisions to GenAI
This means, for instance, if you are in agent-based modelling, like me, and you use object oriented programming, think yourself carefully about how the model is set up, including the use of classes and their relations. This is a high-level design skill that not only will keep you distinguishable from GenAI (hopefully) for the foreseeable future, but also will ensure scientific quality and integrity of your projects.
Understand Key Steps in Your Data Pipeline.
This means, say you need to clean a database before feeding it into further analysis, or into a model, that you should understand all the key code necessary for the data cleaning.
Document AI-Generated Code as You Would Your Own.
Make sure you rewrite the comments on your code even when GenAI already comes up with a set of comments. It often comments in a way that is good for the specific query you made, but not necessarily for understanding the code inside a larger context.
Use GenAI for Repetitive And Very Standard Analytical Tasks.
This means, for instance, you can use GenAI very well for things such as plotting. And on top of that for light analytical elements within, such as fitting and plotting simple linear regressions. GenAI is very unlikely to be erroneous at such tasks, too. Of course you should not do this if it is the very first linear regression model you ever build!
Train Coding outside of Your Routine Work.
I do not want to lose my skill to come up with routine algorithms and tasks (e.g. simple but cool sorting algorithms or array operations). Therefore, I now try to fit in, whenever the schedule allows, some practice sessions on websites like Leetcode or Hackerrank and all GenAI and even websearch off. These are websites for solving coding challenges and popular in the coding community to prepare for job interviews. My personal favorite is Project Euler, but I am also heavily into number theory, so it might not be everyone’s cup of tea.
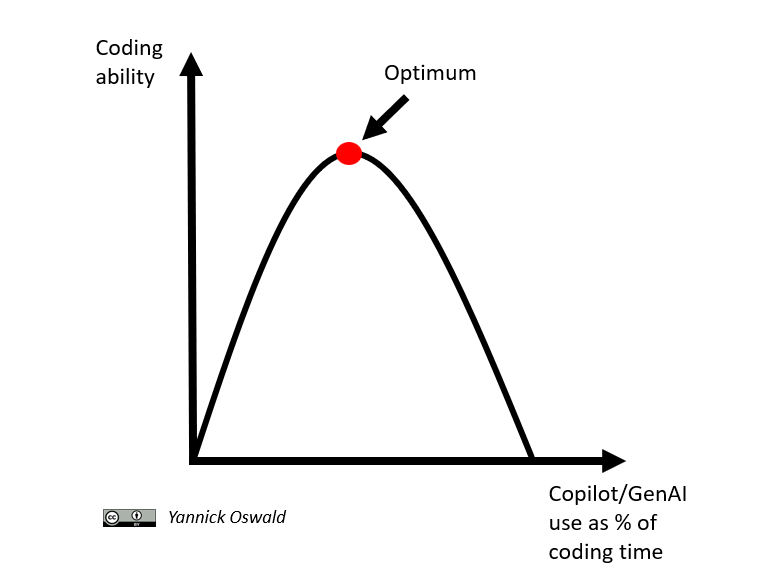
All in all, the gist of my current view is that there is an optimum of using GenAI for coding. Amplify your skills, but do not erode them by using GenAI. It is about staying sharp through controlling all key elements of your code as well as regularly turning of all GenAI and going for little training sessions. Let me know your suggestions for best practices!